| Condition | Participants |
|---|---|
| Total | 231 |
| Assistance | 75 |
| Execution | 76 |
| Information | 4 |
| manual | 76 |
The Impact of AI Execution Autonomy on User Task Performance and Intervention Behavior in Digital Workflows
The Impact of AI Execution Autonomy on User Task Performance and Intervention Behavior in Digital Workflows
Practical Project
Submitted as part of the degree program
“User Experience Management & Design”
In partial fulfillment of the requirements for the degree of
“Master of Science”
PFH Private University Göttingen
May 2026
Written by: Zahra Qasemzadeh
Supervisor: Prof. Dr. Hubert Schüle
Summary
As AI systems increasingly assume execution authority in digital workflows, understanding how different levels of autonomy affect user behavior becomes essential. This study examined the effects of AI execution autonomy on user task performance and intervention behavior in a controlled digital workflow. Using a between-subject experimental design, 160 participants who initiated the task were assigned to one of three autonomy conditions — Manual, Assistance, or Execution — and completed a structured exam registration task via a purpose-built web prototype. Behavioral data were captured through system-generated event logs, enabling objective measurement of task completion time, error occurrence, task abandonment, and intervention frequency. Results provided differentiated support for the proposed hypotheses. Higher levels of AI execution autonomy were associated with significantly shorter completion times, lower error occurrence, and lower task abandonment rates, particularly when comparing the Manual condition with the two system-supported conditions. Intervention occurrence did not differ significantly across conditions; however, intervention count was significantly lower in the Assistance and Execution conditions compared with Manual. Descriptive analysis further revealed that the form of intervention shifted from direct configuration edits in the Manual condition toward override and rejection actions in the system-supported conditions. These findings suggest that AI execution autonomy can improve task efficiency and reduce manual effort without fully removing the user from the interaction process. The results support a design perspective in which autonomy is calibrated to task structure and user control requirements rather than unconditionally maximized.
1 Introduction
Artificial intelligence (AI) systems are increasingly embedded in digital workflows and are evolving from tools that provide decision support toward systems capable of autonomously executing actions. In many contemporary applications, AI no longer functions merely as a source of information or recommendations but actively participates in shaping and executing decisions. This shift from assistance to autonomous execution fundamentally changes the distribution of control, responsibility, and risk between human users and technical systems (Endsley, 2017; Parasuraman et al., 2000).
The distribution of decision authority between humans and automated systems has long been a central concern in human–automation interaction research. Early work conceptualized automation as a continuum of autonomy, ranging from full human control to full system control, and showed that different levels of automation can significantly influence human performance, error behavior, and reliance on automated systems (Parasuraman et al., 2000; Sheridan & Verplank, 1978). However, much of this research has primarily focused on assistive systems in which humans retain primary decision authority.
More recent research in human–computer interaction has increasingly emphasized subjective constructs such as trust, perceived usefulness, and user satisfaction. While these perspectives provide valuable insights, they offer limited understanding of how users behave in concrete task execution scenarios, particularly in systems where AI assumes execution authority. As a result, there remains a lack of empirical, behavior-based evidence on how execution autonomy affects observable task outcomes and user intervention behavior in real interaction contexts (Hoff & Bashir, 2015; Lee & See, 2004).
This study addresses this gap by investigating how different levels of AI execution autonomy affect user task performance and intervention behavior in AI-assisted digital workflows. Specifically, three autonomy levels are examined—manual, assistance, and execution—which represent distinct distributions of decision authority between the user and the system. The analysis focuses on measurable behavioral outcomes, including task completion time, detected errors, abandonment, and intervention frequency, enabling a systematic comparison across conditions.
This leads to the following research question: How does the level of AI execution autonomy affect user task performance and intervention behavior in AI-assisted digital workflows?
The study adopts a controlled experimental design in which user interactions are captured through system-generated logs. Instead of relying on self-reported measures, behavioral data is used to assess how users perform tasks and how often they intervene under different autonomy conditions. By operationalizing AI execution autonomy as a system-level property rather than as a feature of a specific model, the study isolates the effect of execution authority within a controlled task environment. This reflects how AI systems are typically implemented in real-world applications, where autonomy emerges from system design rather than from the underlying model alone.
The contribution of this study lies in providing a behaviorally grounded, log-based analysis of AI execution autonomy. By capturing real user interactions in a controlled setting, the study enables a systematic comparison of task performance and intervention behavior across autonomy levels. The findings contribute to a more empirical understanding of how autonomy shapes human–AI interaction and provide practical insights for designing AI-assisted systems that balance efficiency and user control.
2 Theory
2.1 AI Execution Autonomy
Automation has long been conceptualized as a continuum that differs in the extent to which control is allocated to the machine rather than to the human operator. Early work described levels of automation in terms of how much authority is transferred from the human to the system. Later work extended this view by distinguishing not only levels of automation but also stages of information processing, showing that automation can support or replace the human at different points in the task cycle. This distinction is important because the consequences of automation depend not only on how much control is delegated but also on which function is being delegated (Sheridan & Verplank, 1978; Parasuraman et al., 2000).
Subsequent research has shown that increasing automation is not simply a matter of reducing human effort. Rather, higher levels of automation change the structure of human involvement. Instead of directly performing each task step, the human increasingly supervises, monitors, and selectively intervenes when necessary. This is particularly relevant for contemporary AI systems, which are no longer limited to presenting information or recommendations but can increasingly generate, select, and implement actions within a workflow. In such settings, greater autonomy may improve efficiency, but it can also create new supervisory demands, such as tracking what the system is doing, understanding its operational state, and recognizing when correction is necessary (Endsley, 2017; Sarter & Woods, 1995; Wickens et al., 2010).
These dynamics are also consistent with broader work on flexible human–automation collaboration. Rather than treating automation as a fixed substitution of machine for human, later approaches have argued that the design challenge lies in how control is delegated, negotiated, and retained across task stages. In supervisory settings, the central issue is therefore not only whether automation exists, but how much execution authority is transferred and how much meaningful control remains available to the user (Miller & Parasuraman, 2003; Miller & Parasuraman, 2007).
Against this background, AI execution autonomy in the present study is defined as the extent to which the system independently determines and executes task-related actions within a workflow. This definition emphasizes execution authority rather than mere recommendation. In the Manual condition, execution authority remains with the user and the system performs only validation. In the Assistance condition, the system generates a suggested solution, but the user retains the ability to modify it. In the Execution condition, the system determines the task configuration directly and the user’s role is reduced to acceptance, rejection, or re-selection. These conditions therefore represent qualitatively different allocations of control and provide a concrete operationalization of execution autonomy for empirical comparison.
2.2 User Task Performance
User task performance refers to how effectively and efficiently a task is completed within a given human–system arrangement. In automated and semi-automated environments, performance is not solely a property of the user, but of the joint human–automation system. Automation can improve performance by reducing cognitive demands and supporting routine processing, but such benefits depend strongly on the type and degree of automation implemented (Parasuraman et al., 2000; Parasuraman & Wickens, 2008).
At the same time, prior work has shown that the relationship between automation and performance is not uniformly positive. Automation may be used appropriately, misused, underused, or abused, and each of these patterns can shape whether performance actually improves. Thus, increases in system autonomy do not automatically guarantee better outcomes. Performance gains depend on whether the automation is reliable enough, whether the delegated task is suitable for automation, and whether the human remains capable of effective oversight when needed (Parasuraman & Riley, 1997).
Much of the literature has examined the effects of automation through constructs such as trust, reliance, situation awareness, and workload. These constructs are important because they shape how users interact with automation. However, they do not directly capture whether a task was completed quickly, accurately, and successfully. For execution-oriented AI systems, this distinction becomes particularly important because if the system takes over more of the workflow, its value should also be reflected in observable task outcomes, not only in subjective impressions. Trust-centered perspectives show that trust influences reliance on automation, but they do not by themselves provide a full account of concrete task performance in execution contexts (Lee & See, 2004; Hoff & Bashir, 2015; Dzindolet et al., 2003).
For this reason, the present study conceptualizes user task performance in behavioral terms. Three objective indicators are used: completion time, detected errors, and task abandonment. Completion time captures efficiency, that is, how quickly the task is completed. Detected errors capture breakdowns in valid task execution when system constraints are violated. Task abandonment captures unsuccessful task progression, indicating that task initiation did not lead to completion. Together, these measures provide a direct and observable view of task performance under different levels of AI execution autonomy.
2.3 Intervention Behavior
Whereas task performance captures the outcome of interaction, intervention behavior captures the extent to which users step in and modify, override, or reject the system’s actions during task execution. In human–automation interaction, intervention is closely tied to broader issues of monitoring, reliance, trust, and supervisory control. Appropriate reliance on automation often becomes visible in whether users accept automation outputs or choose to intervene, and higher autonomy does not eliminate the human role but often transforms it into one of supervision and recovery when system output is questioned or needs correction (Lee & See, 2004; Endsley, 2017).
Intervention is theoretically important because it reflects how users respond to different allocations of control. A low level of intervention may indicate that the system output was accepted with little need for correction, but it may also reflect a lack of opportunity to intervene. A high level of intervention may indicate preserved user control, reduced confidence in the system, or the need to correct inadequate system outputs. As a result, intervention should not be interpreted as inherently positive or negative; rather, it provides evidence about how the human–AI relationship is enacted during task execution.
This perspective is strengthened by research on automation bias, algorithm aversion, and flexible delegation. Users do not simply accept or reject automation in a uniform way. They may over-rely on automated outputs, avoid automation after observing errors, or become more willing to use automation when they retain even a small degree of adjustment power over system output. These findings suggest that intervention is not only a sign of distrust or failure, but also an indicator of how users regulate control when interacting with semi-autonomous or execution-oriented systems (Mosier & Skitka, 1999; Dietvorst et al., 2015; Dietvorst et al., 2018; Miller & Parasuraman, 2007).
In the present study, intervention behavior is operationalized through system-logged user actions. Specifically, interventions include edits of task parameters (FIELD_EDIT), overrides of system-generated decisions (OVERRIDE), and rejection or regeneration of outputs (AI_SUGGESTION_REJECTED). This allows intervention to be examined both as a binary occurrence and as a quantitative count. In addition, the specific forms of intervention can be distinguished descriptively, making it possible to examine not only whether users intervened, but also how they intervened.
2.4 Research Gap and Hypotheses
Although human–automation research provides a strong foundation for understanding the distribution of control between people and systems, several limitations remain when this literature is applied to contemporary AI execution contexts. First, much of the established literature has focused on automation broadly defined, often in relation to trust, reliance, workload, and situation awareness rather than on objective, behavior-based outcomes in digital task workflows. Second, a large proportion of prior work has examined assistive or advisory automation, in which the human still retains primary execution authority. As a result, less is known about what happens when AI systems move beyond support and begin to shape or execute task outcomes more directly (Lee & See, 2004; Hoff & Bashir, 2015; Endsley, 2017).
This gap is especially relevant because execution-oriented AI changes the role of the user. When the system not only recommends but also performs workflow-relevant actions, the central design question is no longer simply whether users trust or like the system, but how different levels of execution autonomy affect observable performance and intervention patterns. Existing theories imply that such effects should exist, but they do not yet provide sufficient empirical evidence for behavior-based comparisons in execution-oriented digital workflows. The gap is therefore not only conceptual but also methodological, because objective log-based evidence comparing Manual, Assistance, and Execution conditions remains limited (Parasuraman et al., 2000; Miller & Parasuraman, 2003; Endsley, 2017).
Recent literature also suggests that this gap has become more pressing with the rise of systems that act with greater apparent agency. Research on algorithm aversion and human–automation delegation indicates that user responses to automation are shaped not only by perceived accuracy but also by the degree of retained control and the possibility of correction. This implies that execution autonomy should be studied not only as a technical property of the system, but also as a design condition that reshapes human performance and intervention behavior in measurable ways (Dietvorst et al., 2015; Dietvorst et al., 2018; Miller & Parasuraman, 2007).
To address this gap, the present study examines how different levels of AI execution autonomy affect user task performance and intervention behavior in a controlled digital workflow using system-generated log data. Based on the theoretical expectation that higher execution autonomy can reduce manual effort and alter the need for user intervention, the following hypotheses are proposed:
H1: Higher levels of AI execution autonomy improve user task performance, as reflected in reduced completion time, lower error occurrence, and lower abandonment rates.
H2: Higher levels of AI execution autonomy reduce user intervention during task execution.
3 Methods
3.1 Study Design
This study employed a between-subject experimental design with three conditions representing different levels of AI execution autonomy: Manual, Assistance, and Execution.
Participants were randomly assigned to one of the three conditions and completed a single task within the assigned condition. The between-subject design was chosen to avoid learning effects and to ensure that user behavior was not influenced by prior exposure to other autonomy levels.
3.2 Prototype and Logging
A web-based exam registration system was developed to simulate a realistic academic workflow. The system required users to select a semester, choose an exam period, and configure a valid set of exams under predefined constraints.
User interactions were logged using a backend logging system implemented with Supabase. The logging system captured event-level interaction data, including user actions (e.g., TASK_STARTED, TASK_COMPLETED, ERROR_SHOWN, FIELD_EDIT, OVERRIDE, AI_SUGGESTION_REJECTED), timestamps (client-side and server-side), session identifiers, and the assigned condition (mode). The collected data was stored as structured event logs and exported as CSV files for analysis. This approach enabled a detailed reconstruction of user behavior during task execution.
3.3 Variables
The independent variable (IV) in this study was the level of AI execution autonomy, with three levels: Manual, Assistance, and Execution. The dependent variables (DVs) captured objective behavioral outcomes derived from interaction logs: task completion time, error occurrence, task abandonment, and intervention behavior. These variables were operationalized based on observable interaction events.
3.4 Sample
A total of 231 participants were included in the study. The participant distribution across conditions is shown in Table 1.
An important issue in the dataset is the presence of the “Information” mode, which theoretically should not exist as an active interaction condition. Therefore, it is necessary to investigate why this mode appears in the logs and what type of events have been recorded under it. To assess this, a validity check was conducted by filtering all entries associated with the “Information” mode and inspecting their session IDs and logged actions.
| Session ID | Action |
|---|---|
| S-7QR92FMR | PAGE_VIEW |
| S-KY2JLRYQ | PAGE_VIEW |
| S-NT977W23 | PAGE_VIEW |
| S-OQKZ8TJ1 | PAGE_VIEW |
The inspection showed that the “Information” mode contained only four log entries, all of which were recorded as PAGE_VIEW events. This indicates that these entries reflect passive page access rather than meaningful task-related interaction. Therefore, the “Information” mode was treated as invalid and excluded from further analysis to ensure data quality, cleanliness and consistency.
| Condition | Participants |
|---|---|
| Total | 227 |
| Assistance | 75 |
| Execution | 76 |
| Manual | 76 |
Repeated participation was intended to be prevented by the system design. However, to ensure data validity, an additional check was conducted at the session level, since repeated participation may still occur despite implemented controls in the experimental environment. Therefore, sessions were used to verify that each participant contributed only one observation and to avoid overcounting repeated entries.
| Condition | Sessions |
|---|---|
| Assistance | 75 |
| Execution | 76 |
| Manual | 76 |
The results show a balanced distribution of unique sessions across conditions, indicating that each participant contributed only one observation and that no overcounting occurred.
3.5 Measures
All dependent variables were derived from system-generated event logs and aggregated at the session level.
Task completion time was defined as the time interval between task start and task completion within a session. Specifically, it reflects the elapsed time between the first TASK_STARTED event and the corresponding TASK_COMPLETED event. As this measure requires a valid endpoint, it was calculated only for sessions that were completed successfully.
To complement this efficiency-based measure, task abandonment was included as an indicator of unsuccessful task progression. Task abandonment was defined as sessions in which users initiated but did not complete the task. Thus, a session was classified as abandoned when a TASK_STARTED event was recorded without a corresponding TASK_COMPLETED event. Figure 1 provides an overview of overall task progression across all 224 participants. It shows the number of participants who entered the system but did not start the task, those who started the task but did not complete it, and those who started and successfully completed the task.
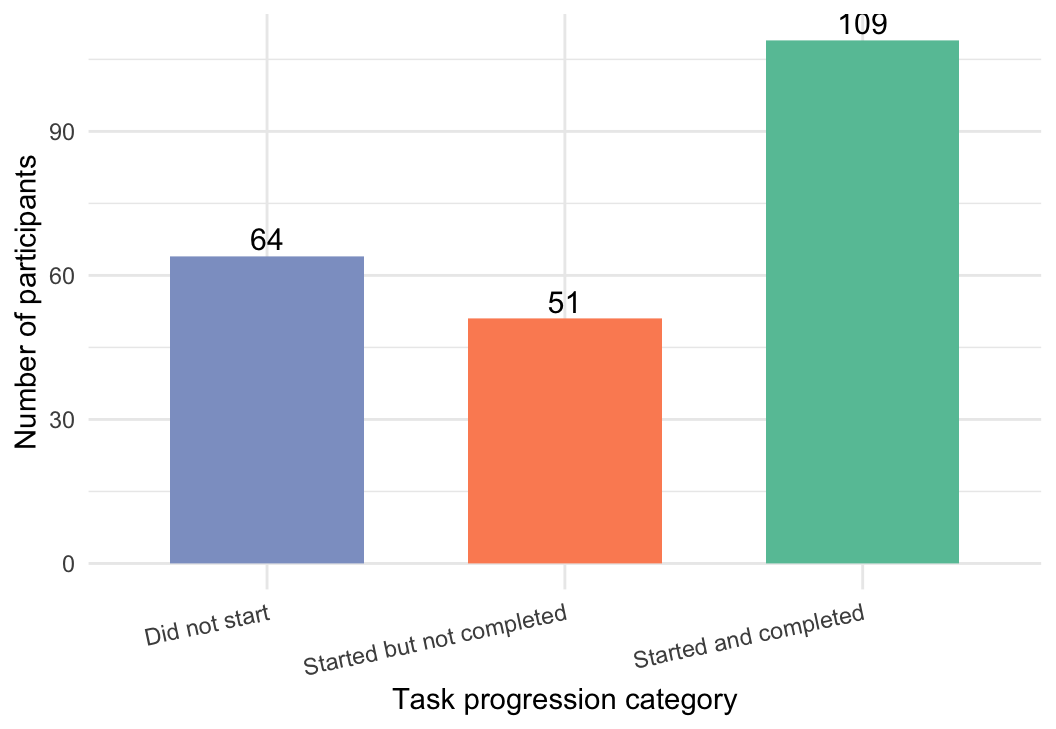
Building on this general overview, Figure 1 first showed overall task progression across the full sample and indicated that 64 participants did not start the task at all. The following analysis therefore focuses only on the 160 participants who initiated the task. Among these started sessions, the aim is to examine how task outcomes were distributed across the three autonomy conditions by distinguishing between participants who started but did not complete the task and those who started and successfully completed it. To display these condition-specific differences more clearly, a grouped bar chart was used in Figure 2.
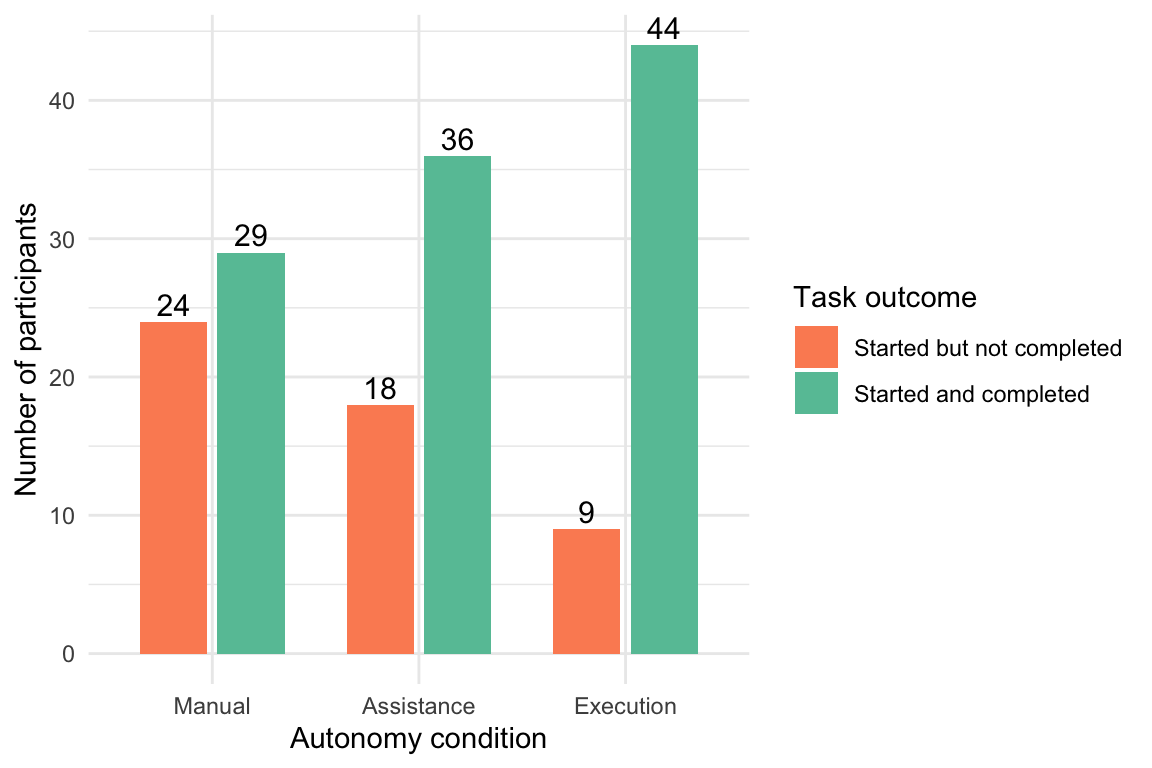
Figure 2 shows the distribution of task outcomes among participants who started the task, separated by autonomy condition. Across all three conditions, completed sessions outnumbered abandoned sessions. The Execution condition showed the highest number of completed sessions and the lowest number of abandoned sessions, whereas the manual condition showed the highest number of abandoned sessions.
Error occurrence was operationalized through ERROR_SHOWN events. Sessions were included in this analysis if a task had been started, regardless of whether the task was later completed or abandoned. This approach ensured that validation problems encountered during task execution were captured independently of final task outcome. Abandoned sessions were retained in the analysis because errors themselves may have contributed to task abandonment. We further examined whether error occurrence differed between completed and abandoned sessions. As shown in Figure 3, a 100% stacked bar chart was used to compare the proportion of sessions with and without errors across the two task outcomes. This visualization makes it possible to assess what percentage of completed sessions contained at least one error and what percentage of abandoned sessions contained at least one error.
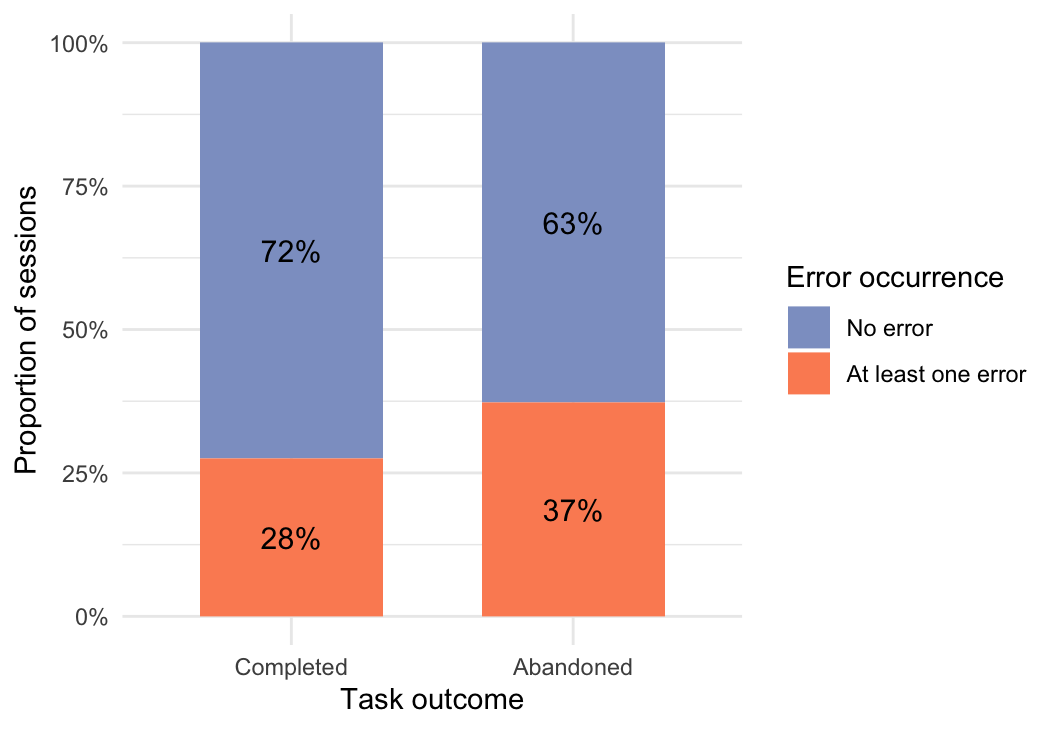
Figure 3 shows the proportion of sessions with and without errors across completed and abandoned started sessions. A higher proportion of abandoned sessions contained at least one error (37%) compared with completed sessions (28%). This pattern suggests that validation errors may have contributed to task abandonment, although no causal conclusion can be drawn from this descriptive comparison alone. To further refine this analysis, error occurrence was examined separately for each autonomy condition. This makes it possible to compare how the proportion of sessions with and without errors differed between completed and abandoned sessions within the Manual, Assistance, and Execution conditions.
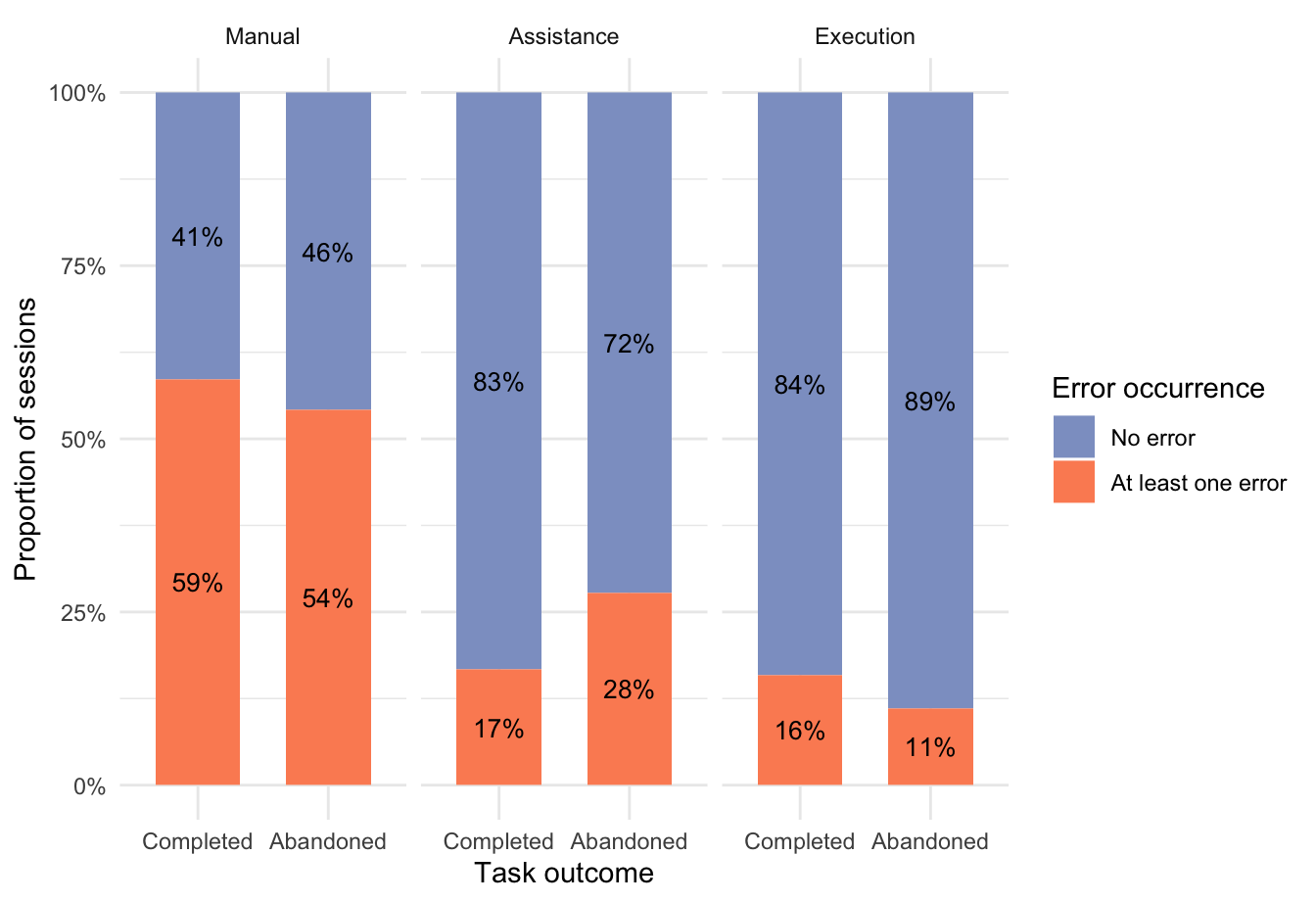
Figure 4 shows that error occurrence varied substantially across autonomy conditions. The Manual condition displayed the highest proportion of sessions with errors in both completed and abandoned sessions, whereas the Execution condition showed the lowest error proportions overall. The Assistance condition fell between these two extremes. At the same time, the relationship between error occurrence and task outcome was not uniform across conditions, suggesting that the role of validation errors may differ depending on the level of AI execution autonomy.
Intervention behavior was operationalized as active user interference with the task configuration or the system output. At the session level, intervention was defined based on the occurrence of FIELD_EDIT, OVERRIDE, and AI_SUGGESTION_REJECTED events. For the following descriptive overview, a binary intervention indicator was used to distinguish between sessions with at least one intervention and sessions without any intervention. Only started sessions were included in this analysis, regardless of whether the task was later completed or abandoned. Intervention should be measured for all started sessions, because it reflects user behavior during task execution rather than successful task completion. Figure 5 shows the proportion of sessions with and without intervention across the three autonomy conditions.
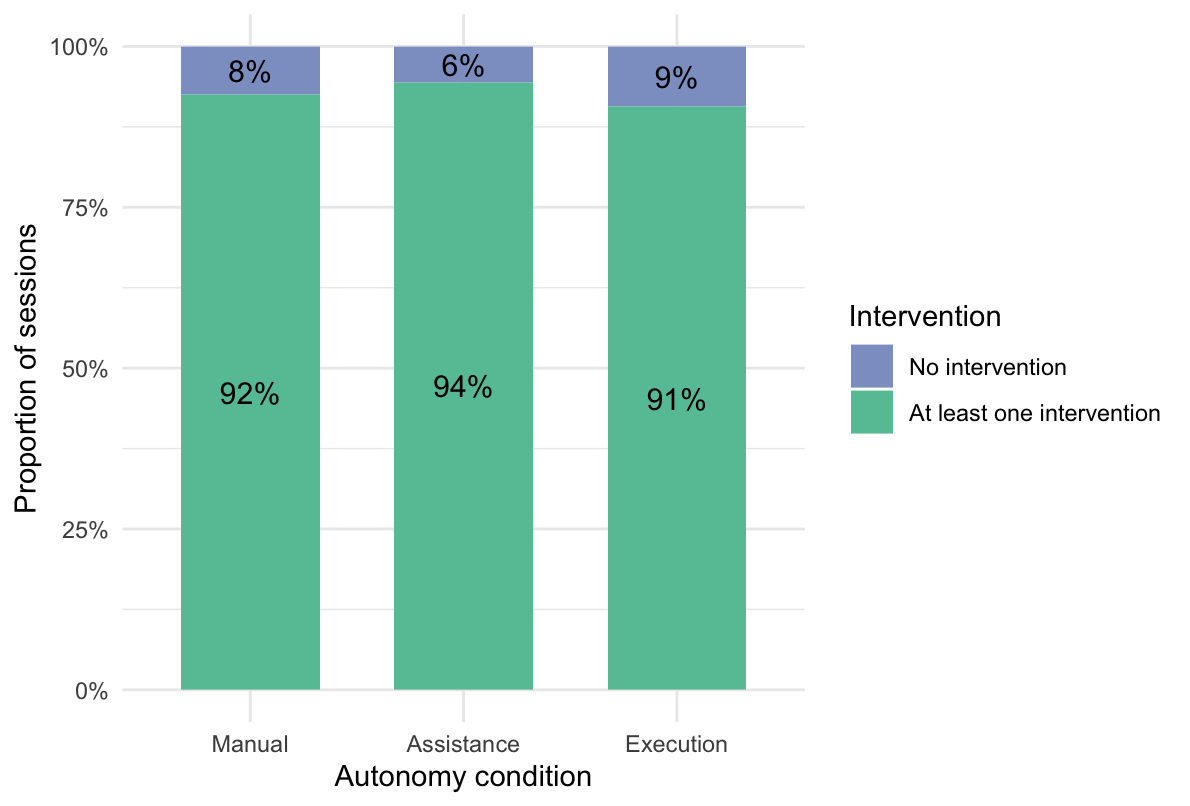
Figure 5 shows that intervention occurred in the large majority of started sessions across all three autonomy conditions. The proportion of sessions with at least one intervention was consistently high in the Manual, Assistance, and Execution conditions, indicating that user intervention was common regardless of autonomy level. At the descriptive level, only minor differences between conditions were observed.
This pattern may indicate that the binary intervention measure captured a very broad range of user actions, thereby limiting its ability to differentiate more clearly between autonomy conditions. Alternatively, it may suggest that intervention was generally required across conditions due to the structure of the task. These interpretations are considered in the discussion.
Figure 6 provides a more fine-grained view of intervention behavior by showing the distribution of intervention counts across the three autonomy conditions. In contrast to the binary intervention indicator used in Figure 5, this analysis captures how often users intervened within a session. Only started sessions were included, as intervention could only occur once task execution had begun.
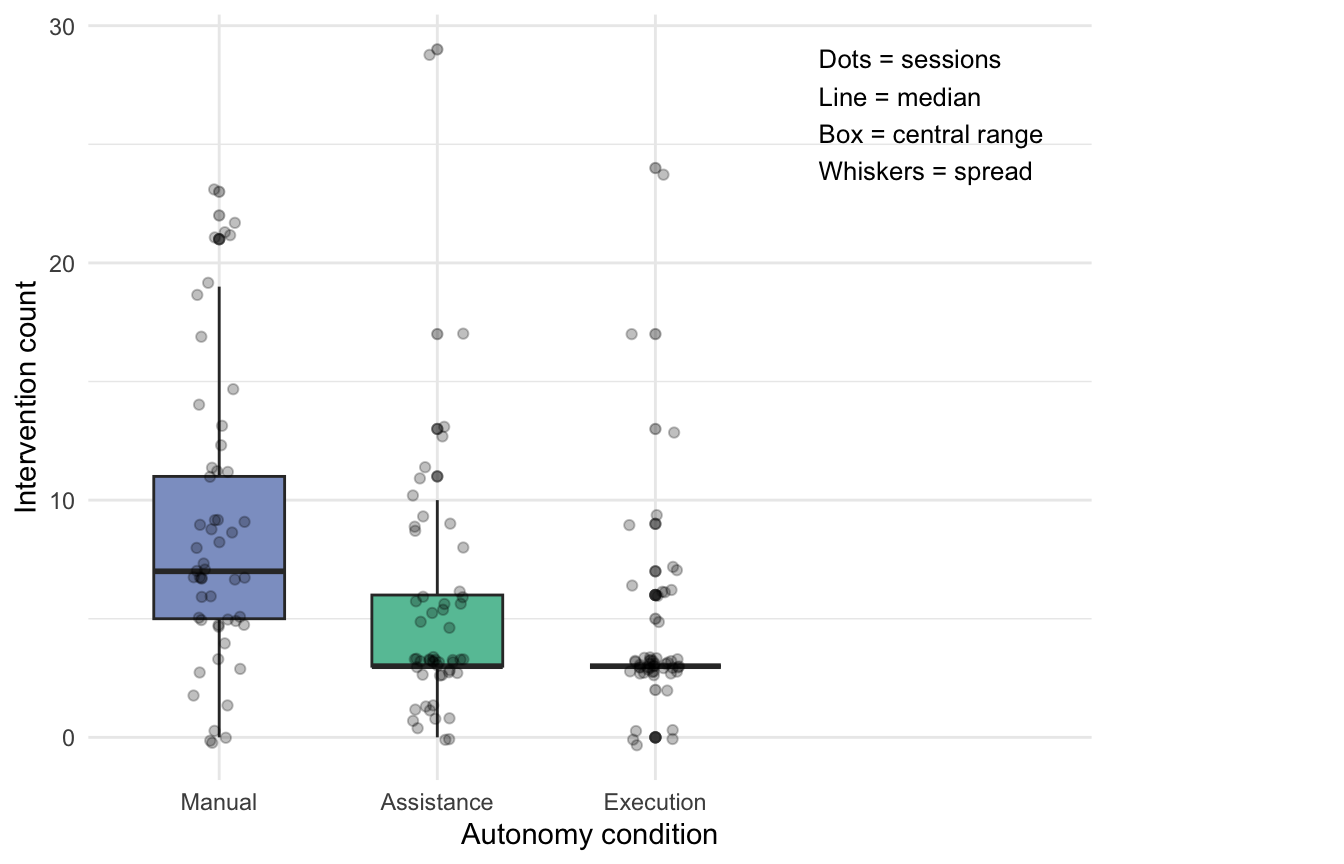
Figure 6 suggests that intervention frequency differed across autonomy conditions. The Manual condition showed the highest intervention counts overall, whereas the Execution condition showed the lowest. The Assistance condition fell between these two extremes. This descriptive pattern is consistent with the expectation that greater execution autonomy reduces the need for user intervention, although formal statistical testing is required to assess whether these differences are significant.
3.6 Data Preparation and Analysis
The raw dataset consisted of event-level interaction logs. Prior to analysis, all entries associated with the Information mode were excluded because they reflected passive PAGE_VIEW events rather than meaningful task-related interaction. In addition, repeated participation was checked at the participant-session level, and no repeated entries were identified. After this cleaning step, the data were aggregated to the session level, so that each session represented one participant’s interaction within one assigned condition.
Based on this session-level aggregation, summary variables were derived for task progress, task completion, abandonment, error occurrence, and intervention behavior. Sessions in which the task was not started were retained for the descriptive overview of overall task progression, but they were excluded from analyses that required actual task execution. Accordingly, abandonment, error occurrence, and intervention behavior were analyzed only for started sessions. Task completion time was calculated only for completed sessions, as this measure required both a valid start point and a valid end point.
Statistical analyses will be conducted according to the measurement level of the respective variables. As task completion time represents a continuous outcome across three autonomy conditions, differences will be examined using a non-parametric Kruskal–Wallis test, followed by pairwise Wilcoxon rank-sum tests where appropriate. Abandonment, error occurrence, and intervention occurrence will be analyzed as categorical outcomes using chi-square and proportion-based tests.
4 Results
This section reports the empirical results in relation to the two hypotheses of the study. First, the effects of AI execution autonomy on task performance are examined, including completion time, detected errors, and task completion versus abandonment. Second, the effects on intervention behavior are presented, covering intervention occurrence, intervention frequency, and the different types of intervention observed across conditions.
4.1 H1: Task Performance
To evaluate H1, task performance was examined across the three autonomy conditions using three outcome dimensions: completion time, detected errors, and task completion versus abandonment. Together, these measures provide an overview of how efficiently and successfully participants performed the task under different levels of AI execution autonomy.
4.1.1 Completion Time
Task completion time was operationalized as the elapsed time between the beginning and the successful completion of task execution within a session. For this measure, TASK_STARTED was treated as the starting point of task execution, and TASK_COMPLETED was treated as the endpoint indicating successful task completion. Because the analysis focused on elapsed interaction time within the system, completion time was calculated using the client-side timestamp variable (client_ts_ms). This timestamp was used because it directly reflects the temporal order and duration of user interactions during task execution. Accordingly, completion time was defined only for sessions in which both a valid task start and a valid task completion event were recorded.
| Condition | Mean | Median | Min | Max |
|---|---|---|---|---|
| Manual | 36.07 | 27.42 | 12.77 | 100.97 |
| Assistance | 26.08 | 18.44 | 6.99 | 95.84 |
| Execution | 84.82 | 11.82 | 5.34 | 2964.74 |
Initial descriptive inspection of completion time suggested substantial skewness, particularly due to very large values in the Execution condition. Therefore, extreme cases were examined before proceeding to inferential analysis. Specifically, the longest completion times were reviewed, and the number of sessions exceeding predefined thresholds was inspected in order to determine whether unusually large values reflected meaningful observations or extreme cases that might distort subsequent comparison.
| session_id | mode | completion_time |
|---|---|---|
| S-E1WBD47E | Execution | 2964.736 |
| S-21WAOP00 | Manual | 100.968 |
| S-F5OFN5A6 | Assistance | 95.845 |
| S-O1IMAN9C | Manual | 94.098 |
| S-ZWN4PELR | Manual | 89.414 |
| S-FRQ1PFYO | Assistance | 84.200 |
| S-7HPZY5JW | Assistance | 67.739 |
| S-HXUZS215 | Execution | 67.577 |
| S-8A4U6AVO | Assistance | 66.537 |
| S-4GNOB2GI | Manual | 55.040 |
| total_completed_sessions | above_300_sec | above_600_sec | max_time |
|---|---|---|---|
| 109 | 1 | 1 | 2964.736 |
The inspection showed that only one completed session exceeded 300 seconds, with a completion time of approximately 2965 seconds. Because this value was substantially larger than all other observations and strongly distorted the overall distribution, it was treated as an extreme outlier and excluded from the completion-time analysis. All remaining completed sessions were retained for the subsequent descriptive and inferential analyses.
| Condition | Mean | Median | Min | Max |
|---|---|---|---|---|
| Manual | 36.07 | 27.42 | 12.77 | 100.97 |
| Assistance | 26.08 | 18.44 | 6.99 | 95.84 |
| Execution | 17.84 | 10.79 | 5.34 | 67.58 |
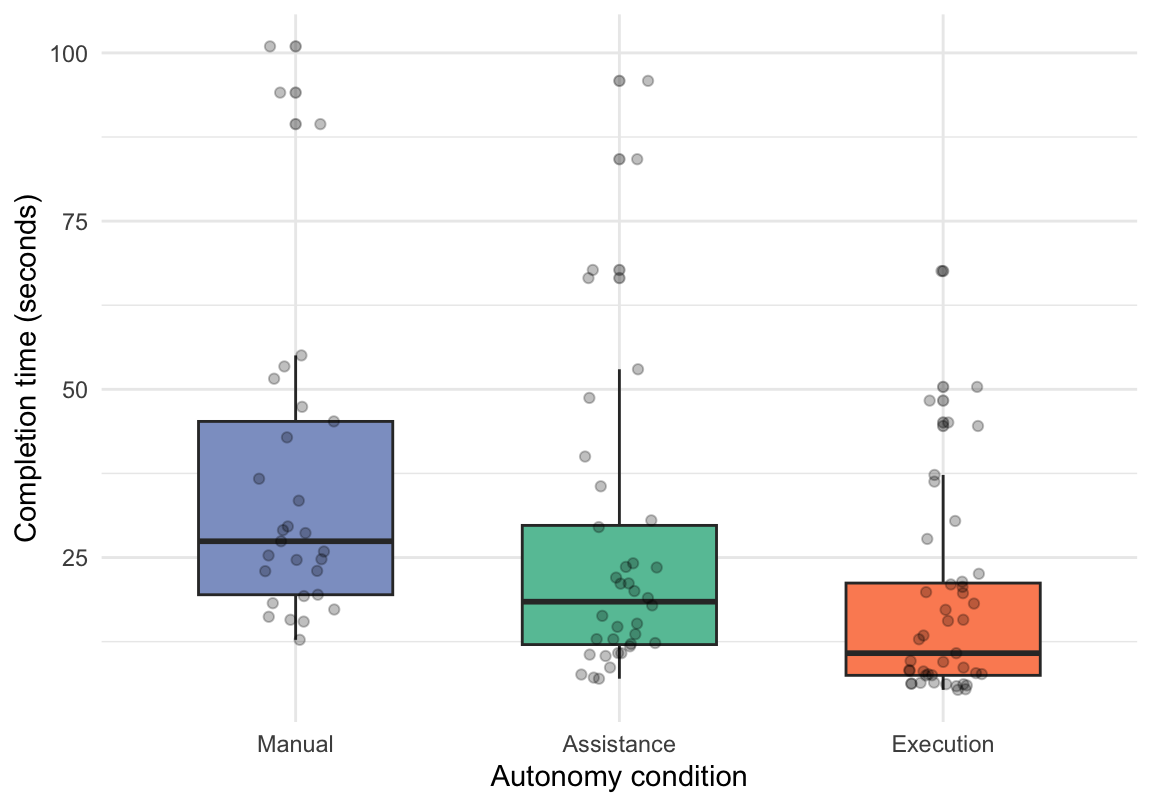
Figure 7 shows the distribution of task completion time across autonomy conditions after exclusion of one extreme outlier. Descriptively, completion time decreased gradually across the three conditions. Median completion time was highest in the Manual condition (27.42 s), followed by the Assistance condition (18.44 s), and lowest in the Execution condition (10.79 s). Mean completion times showed the same ordering, although they were consistently higher than the medians, indicating a slightly right-skewed distribution. Because completion time was compared across three autonomy conditions and the distribution remained slightly right-skewed, a non-parametric Kruskal–Wallis test was used to examine whether completion time differed significantly between conditions. To complement significance testing, an effect size estimate was also calculated for the Kruskal–Wallis result.
| Statistic | df | p-value |
|---|---|---|
| 21.506 | 2 | < .001 |
| ε² | Interpretation |
|---|---|
| 0.186 | relatively large |
A Kruskal–Wallis test revealed a statistically significant overall difference in completion time across the three autonomy conditions, H(2) = 21.51, p < .001, ε² = .186. Thus, the level of AI execution autonomy was significantly associated with variation in task completion time, and the observed effect was comparatively substantial.
Because the Kruskal–Wallis test revealed a significant overall difference in completion time across autonomy conditions, post-hoc pairwise comparisons were performed to determine which specific condition pairs differed significantly. Pairwise Wilcoxon rank-sum tests with Bonferroni correction were used for this purpose.
| Comparison | p-value |
|---|---|
| Assistance vs Manual | 0.0136 |
| Execution vs Manual | < .001 |
| Execution vs Assistance | 0.0367 |
Post-hoc pairwise Wilcoxon comparisons showed that all pairwise comparisons were statistically significant. Completion time was significantly lower in the Assistance condition than in the Manual condition (p = .014), significantly lower in the Execution condition than in the Manual condition (p < .001), and significantly lower in the Execution condition than in the Assistance condition (p = .037). These results indicate a stepwise reduction in completion time as AI execution autonomy increased.
4.1.2 Detected Errors
Detected errors were operationalized based on ERROR_SHOWN events. For the present analysis, all sessions in which the task had been started were included, regardless of whether the task was later completed or abandoned. At the session level, error occurrence was treated as a binary outcome indicating whether at least one validation error was recorded during task execution.
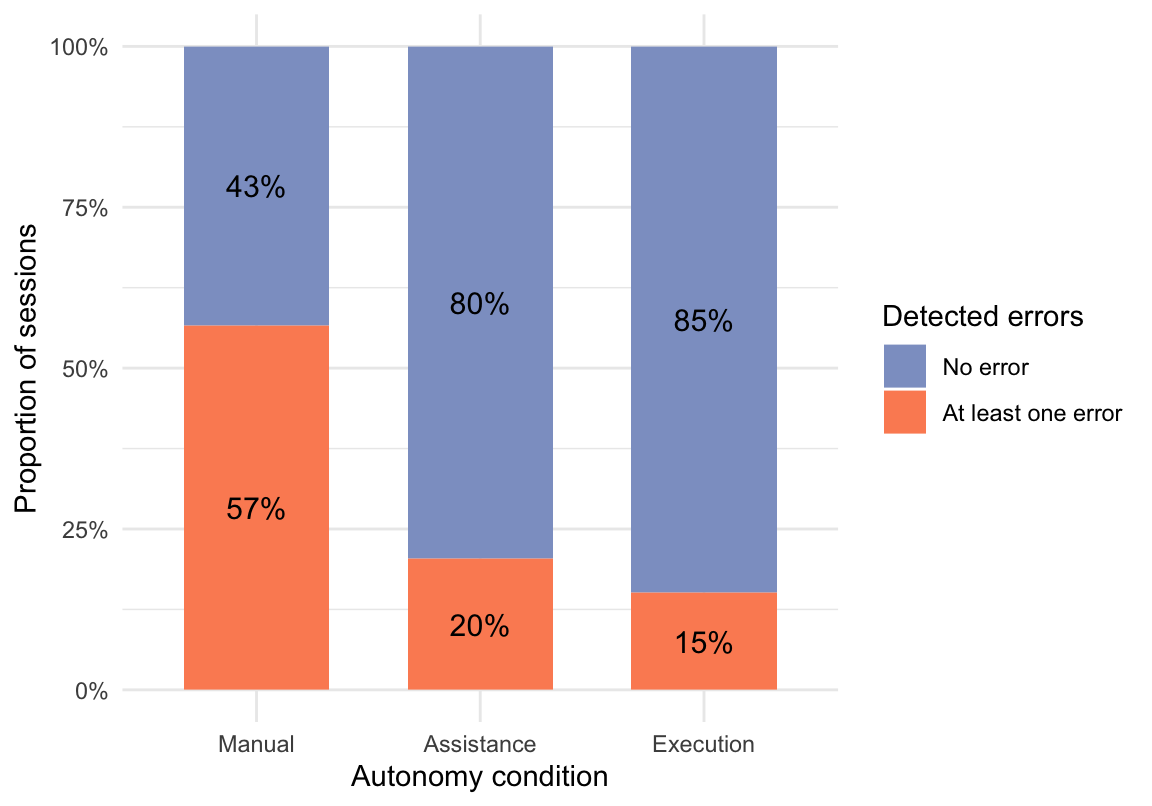
Figure 8 shows the proportion of started sessions with and without at least one detected error across the three autonomy conditions. Descriptively, the Manual condition showed the highest proportion of sessions with at least one detected error, whereas the Assistance and Execution conditions showed substantially lower proportions.
To examine whether detected error occurrence differed across autonomy conditions, a chi-square test of independence was conducted. Because error occurrence was defined as a binary categorical session-level outcome, this test was appropriate for assessing differences in the distribution of error presence across conditions. To complement significance testing, Cramér’s V was calculated as an effect size estimate for the chi-square result.
| Statistic | df | p-value |
|---|---|---|
| 25.525 | 2 | < .001 |
| Cramér’s V | Interpretation |
|---|---|
| 0.399 | medium |
A chi-square test revealed a statistically significant association between autonomy condition and detected error occurrence, χ²(2) = 25.53, p < .001, Cramér’s V = 0.40, indicating a medium effect size. Because the overall test was significant, post-hoc pairwise proportion tests with Bonferroni adjustment were conducted to identify which specific condition pairs differed.
| Comparison | p-value |
|---|---|
| Assistance vs Manual | < .001 |
| Execution vs Manual | < .001 |
| Execution vs Assistance | 1.000 |
Pairwise comparisons showed that the Manual condition differed significantly from both the Assistance condition (p < .001) and the Execution condition (p < .001), whereas no statistically significant difference was found between the Assistance and Execution conditions (p = 1.00). The proportion of started sessions with at least one detected error thus decreased from Manual to both system-supported conditions, but this reduction was statistically significant only when comparing Manual with the other two conditions.
4.1.3 Task Completion and Abandonment
Task completion and abandonment were examined as mutually exclusive outcomes among started sessions. At the session level, a task was classified as completed when a TASK_COMPLETED event was recorded after task initiation. A task was classified as abandoned when a TASK_STARTED event was present but no corresponding TASK_COMPLETED event was recorded.
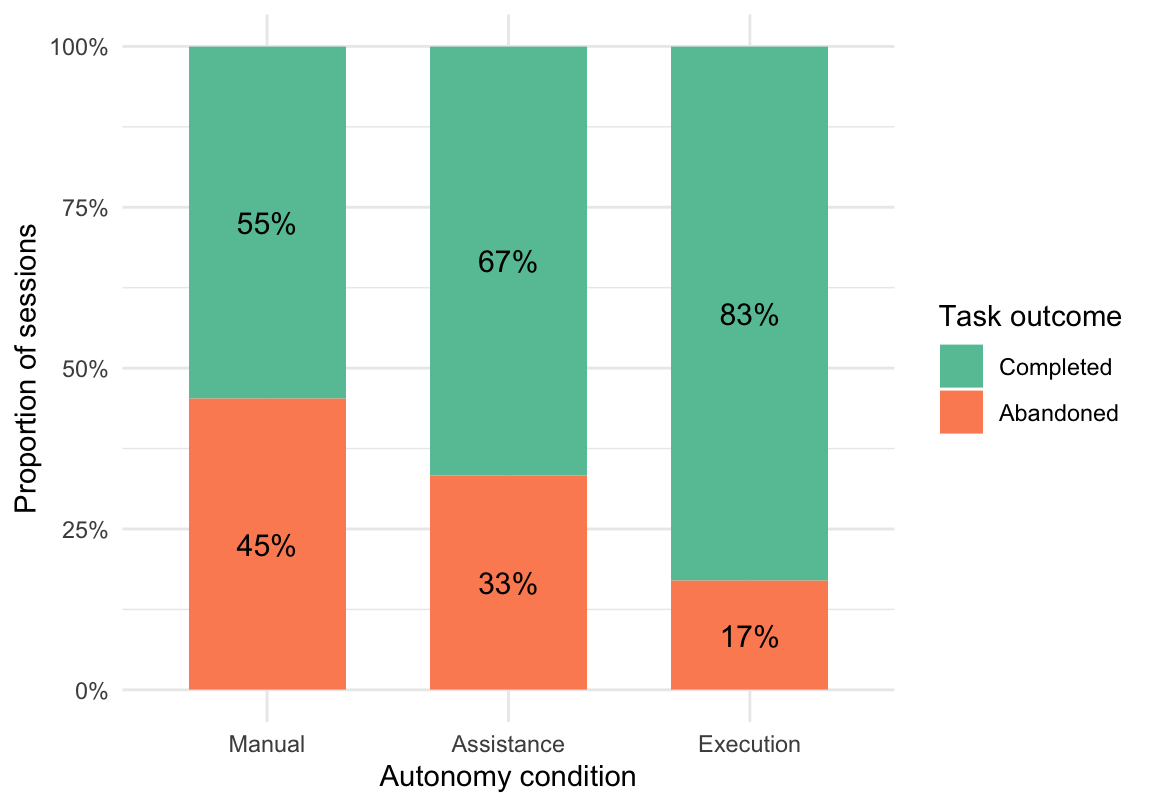
Figure 9 shows the proportion of completed and abandoned sessions among participants who started the task. Descriptively, the Manual condition showed the highest proportion of abandoned sessions (45%), the Assistance condition fell in between (33%), and the Execution condition showed the lowest proportion of abandonment (17%). To examine whether task outcome differed significantly across autonomy conditions, a chi-square test of independence was conducted. Because task completion versus abandonment was treated as a categorical session-level outcome, this test was appropriate for assessing differences in the distribution of task outcomes across conditions. All expected cell frequencies exceeded 5, satisfying the assumption required for the chi-square approximation to be valid. To complement significance testing, Cramér’s V was calculated as an effect size estimate.
| Statistic | df | p-value |
|---|---|---|
| 9.855 | 2 | 0.007 |
| Cramér’s V | Interpretation |
|---|---|
| 0.248 | small |
Because the chi-square test indicated an overall difference across autonomy conditions, additional pairwise proportion tests were conducted to determine which specific pairs of conditions differed in task abandonment. Bonferroni adjustment was applied to control for multiple comparisons.
| Comparison | p-value |
|---|---|
| Assistance vs Manual | 0.857 |
| Execution vs Manual | 0.010 |
| Execution vs Assistance | 0.254 |
To further quantify the magnitude of differences between conditions, odds ratios with 95% confidence intervals were computed for each pairwise comparison.
| Comparison | Odds Ratio | 95% CI |
|---|---|---|
| Manual vs Assistance | 1.66 | [0.76, 3.62] |
| Manual vs Execution | 4.05 | [1.65, 9.93] |
| Assistance vs Execution | 2.44 | [0.98, 6.09] |
The chi-square test showed that task outcome differed significantly across autonomy conditions, χ²(2) = 9.86, p = .007, Cramér’s V = 0.25. Post-hoc pairwise proportion tests showed that the Execution condition differed significantly from the Manual condition (p = .010). The corresponding odds ratio indicated that the odds of task abandonment in the Manual condition were approximately four times higher than in the Execution condition (OR = 4.05, 95% CI [1.65, 9.93]). No significant differences were found between the Assistance and Manual conditions (p = .857; OR = 1.66, 95% CI [0.76, 3.62]) or between the Execution and Assistance conditions (p = .254; OR = 2.44, 95% CI [0.98, 6.09]), though the latter comparison was numerically notable with a CI that narrowly included 1. Overall, these results suggest that higher AI execution autonomy was associated with substantially reduced task abandonment, most clearly when comparing the Execution condition to the Manual condition.
4.2 H2: Intervention Behavior
To evaluate H2, intervention behavior was examined across the three autonomy conditions using three complementary indicators: intervention occurrence, intervention count, and the specific types of intervention observed during task execution. Together, these measures provide a more detailed picture of how strongly users interfered with the system under different levels of AI execution autonomy.
4.2.1 Intervention Occurrence
Intervention occurrence was operationalized as a binary session-level outcome indicating whether at least one intervention took place during task execution. A session was classified as involving intervention if at least one FIELD_EDIT, OVERRIDE, or AI_SUGGESTION_REJECTED event was recorded. Only started sessions were included in this analysis, regardless of whether the task was later completed or abandoned.
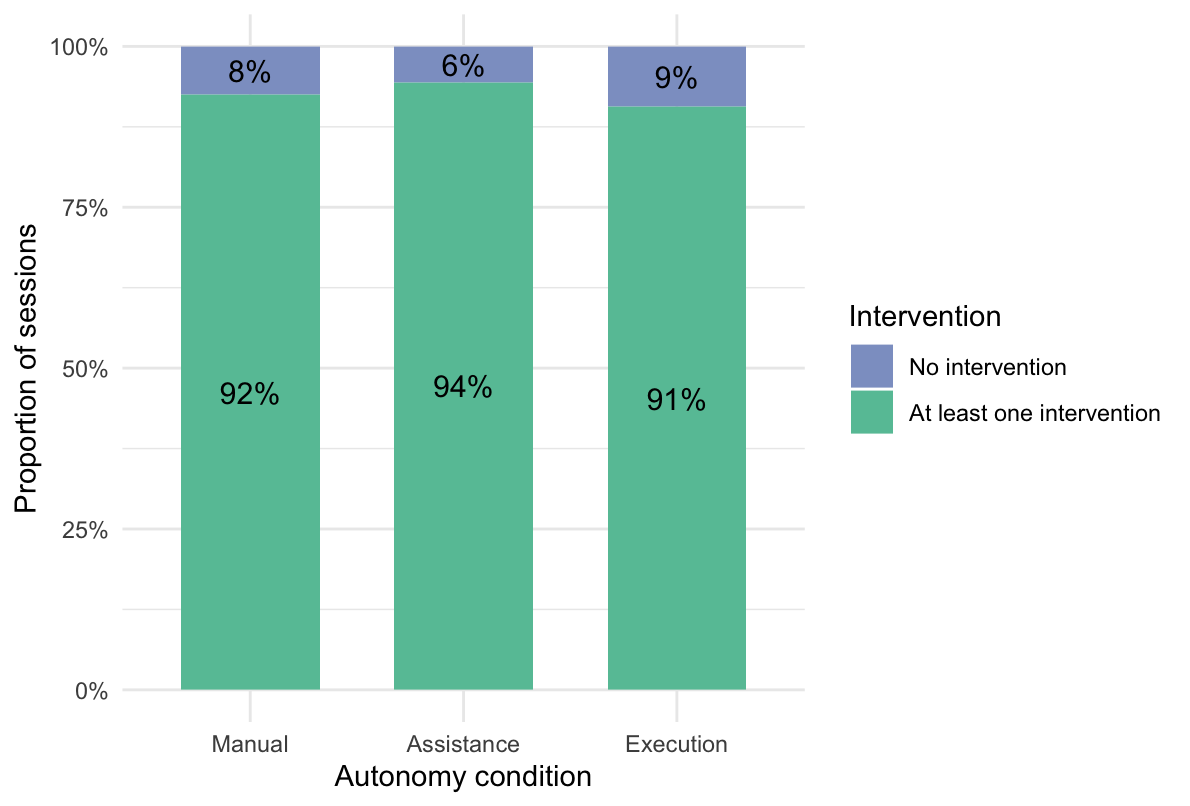
Figure 10 shows the proportion of started sessions with and without intervention across the three autonomy conditions. Descriptively, intervention occurred in the large majority of started sessions in all three conditions. The proportions were very similar across Manual (92%), Assistance (94%), and Execution (91%), indicating only minor descriptive differences in intervention occurrence between autonomy conditions. To examine whether intervention occurrence differed significantly across autonomy conditions, a chi-square test of independence was conducted. Because intervention occurrence was treated as a categorical session-level outcome, this test was appropriate for assessing differences in the distribution of intervention presence across conditions. All expected cell frequencies exceeded 5, satisfying the assumption required for the chi-square approximation to be valid. To complement significance testing, Cramér’s V was calculated as an effect size estimate.
| Statistic | df | p-value |
|---|---|---|
| 0.58 | 2 | 0.748 |
| Cramér’s V | Interpretation |
|---|---|
| 0.06 | small |
The chi-square test showed that intervention occurrence did not differ significantly across autonomy conditions, χ²(2) = 0.58, p = .748, Cramér’s V = 0.06. This indicates that the proportion of started sessions containing at least one intervention was similarly high across the Manual, Assistance, and Execution conditions. Overall, these results suggest that intervention occurrence, as a binary measure, did not clearly distinguish between levels of AI execution autonomy.
4.2.2 Intervention Count
In addition to intervention occurrence, intervention count was examined to capture how often users intervened within a session. At the session level, intervention count was calculated as the sum of FIELD_EDIT, OVERRIDE, and AI_SUGGESTION_REJECTED events. Only started sessions were included, as intervention could only occur once task execution had begun.
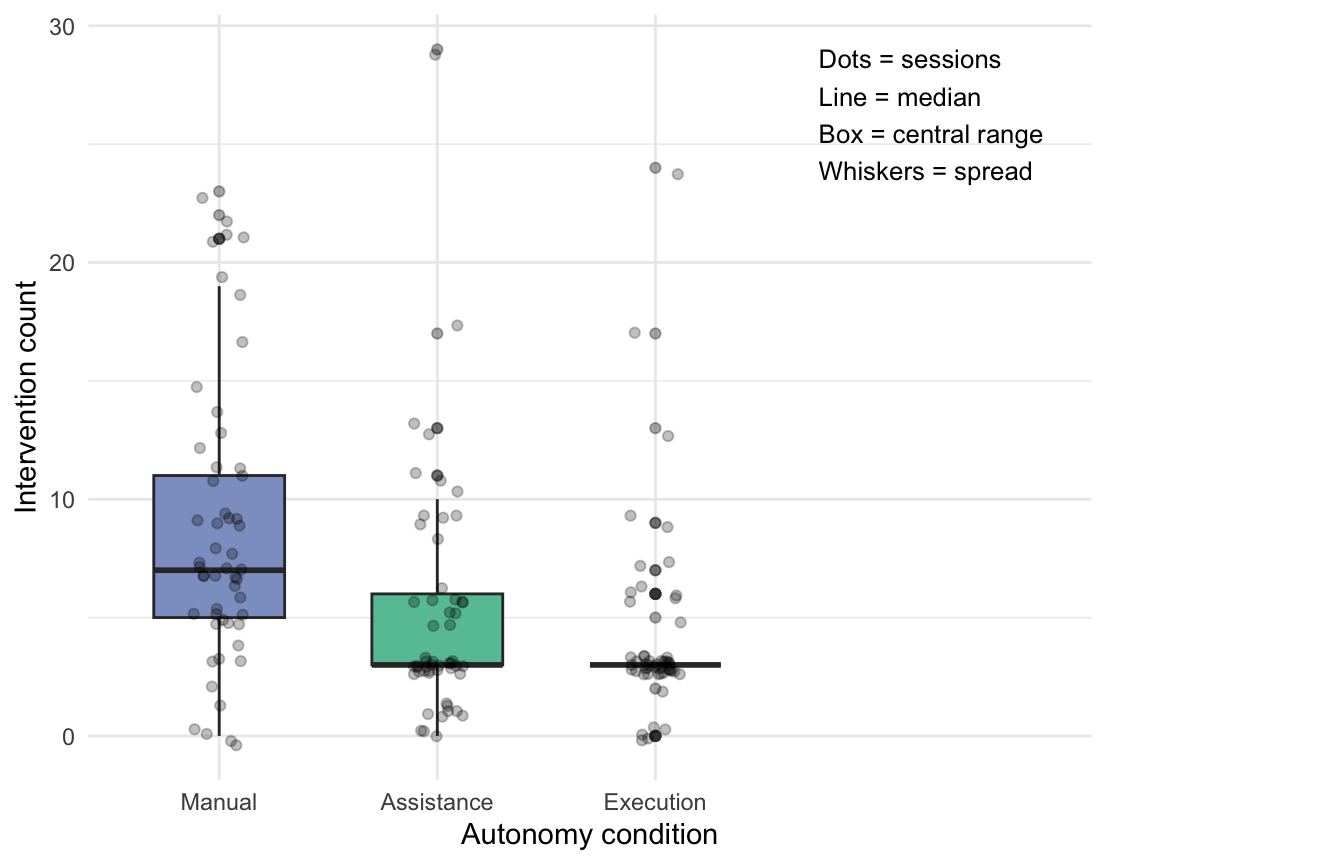
| Condition | n | Median | IQR | Mean |
|---|---|---|---|---|
| Manual | 53 | 7 | 6 | 8.7 |
| Assistance | 54 | 3 | 3 | 5.1 |
| Execution | 53 | 3 | 0 | 4.2 |
Descriptively, Figure 11 and the descriptive statistics below suggest that intervention count differed across autonomy conditions. The Manual condition showed the highest median intervention count (Mdn = 7, IQR = 6), while both the Assistance and Execution conditions showed substantially lower medians (Mdn = 3 for both). Although the medians were equal for Assistance and Execution, the Execution condition displayed notably less spread (IQR = 0 vs. IQR = 3) and a lower mean (4.2 vs. 5.1), indicating that intervention frequency was not only lower but also more consistent in the Execution condition. The Manual condition also displayed the greatest spread, indicating that intervention frequency was both higher and more variable under fully manual operation.
Because intervention count represents a count-based session-level outcome and the distribution was visibly non-normal, a non-parametric Kruskal–Wallis test was conducted to examine whether intervention count differed significantly across autonomy conditions.
| Statistic | df | p-value |
|---|---|---|
| 26.693 | 2 | < .001 |
| ε² | Interpretation |
|---|---|
| 0.157 | large |
A Kruskal–Wallis test showed that intervention count differed significantly across autonomy conditions, H(2) = 26.69, p < .001, ε² = .157. The effect size indicates a large association between autonomy condition and intervention frequency. Because the Kruskal–Wallis test indicated an overall difference in intervention count across conditions, additional post-hoc pairwise Wilcoxon rank-sum tests were conducted. Bonferroni adjustment was applied to control for multiple comparisons.
| Comparison | p-value | r (rank-biserial) |
|---|---|---|
| Assistance vs Manual | < .001 | -0.415 |
| Execution vs Manual | < .001 | -0.546 |
| Execution vs Assistance | 1.000 | -0.098 |
Post-hoc pairwise Wilcoxon comparisons showed that intervention count was significantly lower in the Assistance condition than in the Manual condition (p < .001, r = −0.42) and significantly lower in the Execution condition than in the Manual condition (p < .001, r = −0.55), indicating medium-to-large effects. No significant difference was found between the Assistance and Execution conditions (p = 1.00, r = −0.10). Overall, these results indicate that higher AI execution autonomy was associated with a substantially lower frequency of user intervention compared with the Manual condition, although the difference between Assistance and Execution was not statistically significant.
4.2.3 Types of Intervention
To further differentiate intervention behavior, the specific types of intervention were examined using a behavior-based taxonomy rather than raw UI event labels. Raw log events were semantically recoded to reflect what users were actually able to do in each condition: in the Manual condition, users could only perform direct field edits; in the Assistance condition, users could edit fields directly, override AI suggestions, or reject suggestions; in the Execution condition, users could not edit fields directly — they could only accept, skip, or request a new AI suggestion. Three behavioral categories were therefore defined: Direct Editing, Suggestion Rejection / Regeneration, and Override.
Methodological note on event recoding: Several raw interaction events required semantic reinterpretation to avoid cross-condition confounding. In the Execution condition, FIELD_EDIT events were triggered by dropdown interactions (semester selection) and UI state changes — not by direct content editing, which was structurally unavailable in this condition. Accordingly, FIELD_EDIT is classified as Not Available for Execution and excluded from the Direct Editing category. Conversely, skip_execution_preview events — logged under the OVERRIDE event type in the raw data — were reclassified as Suggestion Rejection / Regeneration behavior, reflecting their functional equivalence to the AI_SUGGESTION_REJECTED action in the Assistance condition. All other OVERRIDE events in the Execution condition (e.g., manual_edit_request, change_semester_after_suggestion) were retained under Override.
Because behavioral availability differed by condition, the analysis strategy was adapted accordingly. Direct Editing was examined only in the Manual and Assistance conditions (where it was available), using a Fisher’s exact test. Override and Rejection occurrence were tested across all three conditions using Fisher’s exact tests, which were preferred over chi-square because some observed cell counts were zero.
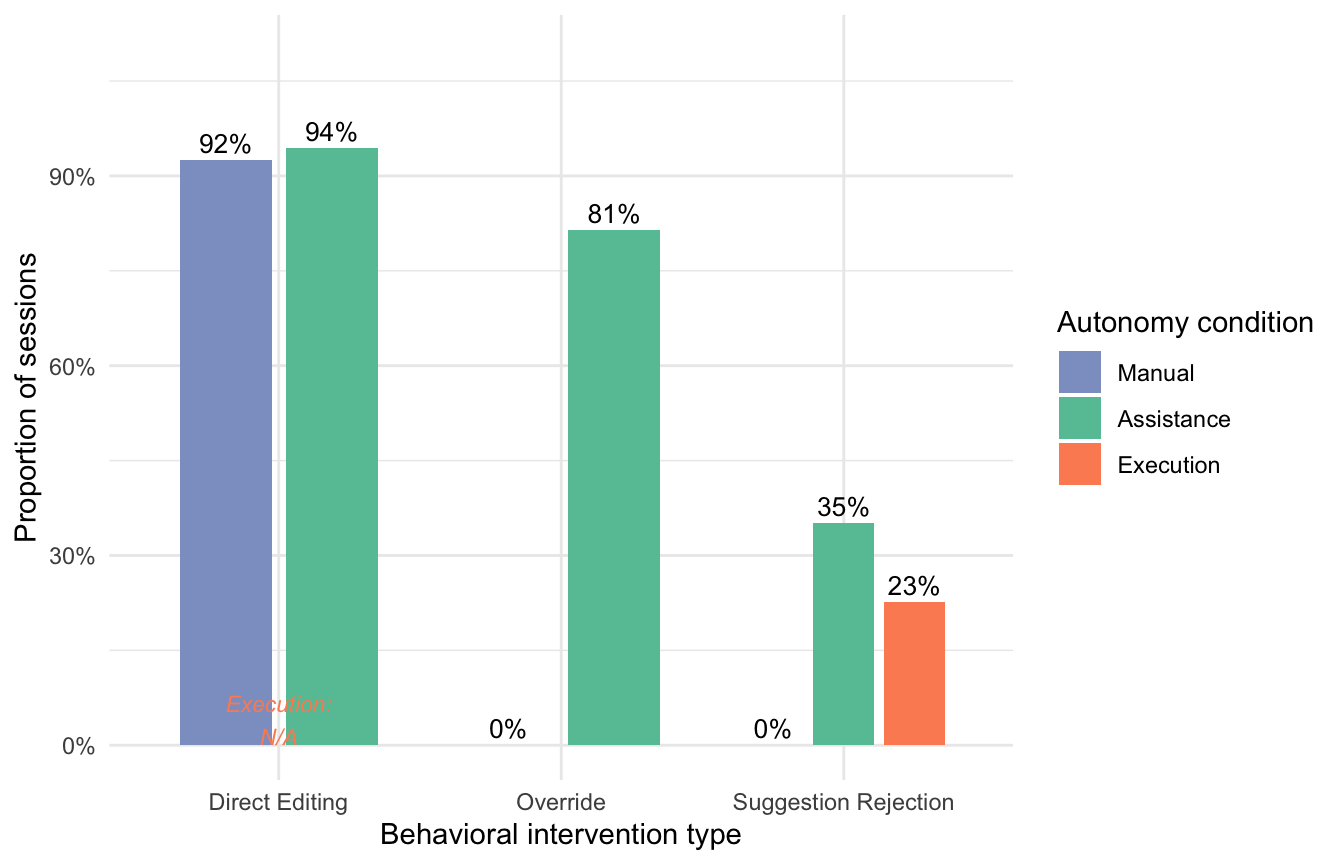
Figure 12 shows the proportion of started sessions containing each behavioral intervention type across the three autonomy conditions. Direct Editing was available in the Manual and Assistance conditions, where it was highly prevalent (Manual: 92%, Assistance: 94%). Direct Editing was not structurally available in the Execution condition and is therefore excluded from that condition’s display. Override occurred in the Assistance (81%) and Execution (89%) conditions and was absent in the Manual condition, reflecting the fact that override behavior presupposes an AI-generated suggestion. Suggestion Rejection / Regeneration was present in both the Assistance condition (35%, via the reject action) and the Execution condition (23%, via skip/regeneration), and was absent in the Manual condition.
| Behavioral Category | Fisher’s p-value |
|---|---|
| Direct Editing (Manual vs. Assistance only) | 0.716 |
| Suggestion Rejection | < .001 |
| Override | < .001 |
Fisher’s exact tests confirmed significant differences across conditions for Override (p < .001) and Suggestion Rejection (p < .001). Direct Editing did not differ significantly between the Manual and Assistance conditions (p = .716), reflecting near-ceiling rates in both (92% and 94%, respectively). The pattern for Override reflects the structural logic of the system-supported conditions: override behavior presupposes an AI-generated suggestion and is therefore only possible in the Assistance and Execution conditions. The pattern for Suggestion Rejection shows that rejection or regeneration behavior was not exclusive to the Assistance condition — Execution users also engaged in rejection-like behavior via the skip/regenerate function (23%), though at a lower rate than Assistance users (35%), who could explicitly reject AI suggestions at any point.
Taken together, the results provide partial support for H2. While intervention occurrence did not differ significantly across autonomy conditions, intervention count showed that users in the Manual condition intervened significantly more often than users in the Assistance and Execution conditions. The behavioral analysis of intervention types further showed that intervention was not uniform across conditions: Direct Editing was available and common in the Manual and Assistance conditions but structurally absent in the Execution condition; Override was concentrated in the system-supported conditions; and Suggestion Rejection / Regeneration was present in both the Assistance and Execution conditions, though at a higher rate in the Assistance condition (35% vs. 23%). Overall, these findings suggest that higher AI execution autonomy did not eliminate intervention altogether, but it reduced how frequently users needed to intervene and changed the form that intervention took.
5 Discussion
5.1 Evaluation of Hypotheses
The present study examined how different levels of AI execution autonomy influenced user task performance and intervention behavior in a controlled digital workflow. Overall, the findings provide differentiated support for the proposed hypotheses.
H1 was largely supported. Higher levels of AI execution autonomy were associated with improved task performance across multiple indicators. For completion time, a clear and statistically significant stepwise pattern was observed, with the Manual condition showing the longest completion times, the Assistance condition showing shorter times, and the Execution condition showing the shortest times. This finding suggests that increasing execution autonomy can reduce the amount of manual effort required to complete a task. For detected errors, the Manual condition showed a significantly higher proportion of started sessions with at least one error compared with both the Assistance and Execution conditions, whereas the difference between Assistance and Execution was not statistically significant. A similar pattern emerged for task completion versus abandonment: overall differences across conditions were significant, but the clearest pairwise difference was found between the Manual and Execution conditions. Taken together, these results indicate that higher execution autonomy improved task performance, although this effect was not equally strong across all performance indicators.
H2 was only partially supported. Intervention occurrence, operationalized as whether any intervention took place during a started session, did not differ significantly across autonomy conditions. In contrast, intervention count showed a significant effect: participants in the Manual condition intervened significantly more often than participants in both the Assistance and Execution conditions, whereas no significant difference was found between the Assistance and Execution conditions. The behavioral analysis of intervention types also showed that intervention was not uniform across conditions. Direct Editing was available and common in the Manual and Assistance conditions but was structurally unavailable in the Execution condition. Override was present in both system-supported conditions and absent in the Manual condition. Suggestion Rejection / Regeneration behavior was observed in both the Assistance and Execution conditions, albeit at a lower rate in Execution (23% vs. 35%), and was absent in the Manual condition. Thus, higher AI execution autonomy did not eliminate intervention altogether, but it did reduce how often users needed to intervene and altered the form that intervention took.
5.2 Summary of Findings
Several overarching findings emerge from the results. First, increasing AI execution autonomy was associated with more efficient task completion. Completion time decreased progressively from the Manual condition to the Assistance condition and further to the Execution condition. Second, higher autonomy was associated with fewer detected errors, particularly when comparing the Manual condition with the two system-supported conditions. Third, abandonment decreased under higher autonomy, although this effect was most clearly evident in the comparison between the Manual and Execution conditions. Fourth, intervention behavior was more complex than initially expected. While intervention occurrence remained high across all conditions, intervention count decreased under higher autonomy. Additionally, the type of intervention differed meaningfully by condition: Direct Editing was exclusive to the Manual and Assistance conditions; Override and Suggestion Rejection / Regeneration were concentrated in the system-supported conditions. This suggests that users continued to engage with the system across all conditions, but the amount of intervention required was lower when the system took over a larger share of task execution, and the nature of that intervention shifted from content editing toward supervisory control.
Taken together, these findings suggest that AI execution autonomy primarily improved task performance by reducing manual workload and limiting the number of corrective actions required during task execution. At the same time, user involvement was not removed entirely, indicating that even execution-oriented systems still operate within a human-supervised interaction structure.
5.3 Interpretation
The observed pattern suggests that the level of execution autonomy influenced not only how quickly tasks were completed, but also how much corrective interaction was needed during task execution. This is consistent with human–automation research showing that delegating more task-relevant processing to the system can improve performance when the system operates within a well-defined and rule-based environment (Parasuraman et al., 2000; Parasuraman & Wickens, 2008). In the present study, both the Assistance and Execution conditions reduced the burden of manual configuration compared with the Manual condition, which likely contributed to the shorter completion times and lower error occurrence in those conditions.
The particularly strong effect on completion time suggests that execution autonomy was especially effective in reducing routine task effort. This pattern is plausible because the experimental task involved structured decisions under explicit constraints. In such settings, higher levels of autonomy can reduce the need for users to manually construct a valid solution step by step. Instead, the system can perform part or all of the configuration work, thereby accelerating task completion. This interpretation aligns with prior research showing that automation can improve efficiency when the delegated function is well specified and computationally manageable (Parasuraman et al., 2000; Parasuraman & Wickens, 2008).
At the same time, the findings show that the relationship between autonomy and intervention is more nuanced than a simple reduction model would suggest. Intervention occurrence remained similarly high across all conditions, whereas intervention count differed significantly. This indicates that a binary distinction between intervention and no intervention was too coarse to capture meaningful differences between conditions. One likely reason is that the operationalization of intervention occurrence was broad, because even a single edit counted as intervention. As a result, the majority of started sessions across all conditions were classified as involving intervention, which limited the discriminative power of this measure. By contrast, intervention count provided a more fine-grained view and showed that the Manual condition required substantially more intervention overall.
The descriptive analysis of intervention types helps explain this pattern further. Edits occurred in more than 90% of started sessions across all conditions, suggesting that editing behavior was a general feature of the task rather than a condition-specific response. This may indicate that some level of active user involvement was structurally embedded in the workflow itself. In contrast, override and rejection-related actions were concentrated in the system-supported conditions. This pattern is theoretically meaningful because it suggests that as autonomy increases, user intervention shifts from constructing the solution manually toward monitoring and selectively correcting the system’s output. Such a shift is consistent with the view that greater autonomy does not remove the human from the loop, but changes the human role from primary executor to supervisor and corrector (Lee & See, 2004; Endsley, 2017; Miller & Parasuraman, 2007).
Another important finding is that the Assistance and Execution conditions were not consistently distinguishable across all outcomes. Although Execution performed better descriptively on several indicators, the pairwise comparisons between Assistance and Execution were often not statistically significant, especially for detected errors and intervention count. This suggests that once the system assumes a meaningful supportive role, additional increases in execution autonomy may yield diminishing returns. In other words, moving from no system support to partial system support may produce the strongest behavioral improvement, whereas moving from partial support to full execution may not always create an equally large additional benefit. This interpretation is important because it suggests that the optimal level of autonomy may not always be full execution. Under some circumstances, assistance-oriented autonomy may already deliver most of the practical benefits while preserving a greater degree of user control. This view is also compatible with work showing that people may prefer modifiable or partially adjustable algorithmic support over fully fixed automated output (Dietvorst et al., 2018; Miller & Parasuraman, 2007).
The present findings also suggest that higher execution autonomy should not automatically be interpreted as the elimination of human involvement. Classical work on the ironies of automation has shown that increasing system autonomy can shift the human role toward supervision and create new demands for intervention when the automated process requires recovery or correction (Bainbridge, 1983). Similarly, research on supervisory control and mode awareness shows that when automated systems become more capable, the human task does not disappear but changes in character, often becoming more dependent on monitoring, interpretation, and timely intervention (Sarter & Woods, 1995; Endsley, 2017). In this study, that broader pattern is visible in the continued presence of intervention even under higher autonomy conditions.
Overall, the findings indicate that AI execution autonomy influenced behavior in two main ways: it improved task performance and reduced the frequency of intervention, but it did not fully remove the need for user involvement. This suggests that execution-oriented AI should not be understood as replacing the user completely. Rather, it restructures the interaction so that users engage less in direct configuration and more in supervision, acceptance, modification, and correction.
5.4 Theoretical Contributions
The findings extend human–automation interaction theory in two substantive directions. First, they provide behavioral evidence for the consequences of execution-oriented AI that complements the predominance of advisory and decision-support automation in existing empirical work. Prior research has established extensively that automation affects trust, situation awareness, reliance, and workload, but these outcomes have been assessed predominantly through self-report instruments and under conditions in which humans retain final execution authority (Lee & See, 2004; Parasuraman & Riley, 1997). The present study demonstrates that when AI systems assume the authority to implement workflow actions directly, the effects are observable in objective behavioral metrics — task duration, error rates, and the frequency and type of user intervention — independently of subjective mediation. This supports the position that execution-oriented AI constitutes a qualitatively distinct object of inquiry that requires behavioral, not solely attitudinal, methods of investigation.
Second, the pattern of diminishing marginal returns to autonomy extends the theoretical understanding of how autonomy levels relate to behavioral outcomes beyond the prevailing assumption of monotonicity. The finding that the functional boundary between unsupported and system-supported execution is more behaviorally consequential than the boundary between assisted and fully autonomous execution qualifies the implicit premise that more automation yields proportionally more of its predicted effects. For the task environment examined here, the relevant design question appears to be whether to cross the threshold from unsupported to system-supported execution, not how far beyond that threshold to proceed. This reframing has implications for how the autonomy design space is conceptualized and for how empirical comparisons between automation levels are structured in future research.
5.5 Limitations
Several limitations should be considered when interpreting the findings. First, the study was conducted with a finite sample in a single controlled experimental setting. Although the sample was sufficient to detect several meaningful differences between conditions, the findings should not be generalized too broadly without caution. Future studies with larger and more diverse samples would strengthen the external validity of the results.
Second, the study was based on a prototype workflow rather than a fully deployed real-world AI system. Although the prototype allowed precise control over autonomy conditions and enabled detailed log-based measurement, it necessarily simplified some aspects of real human–AI interaction. In particular, the system simulated AI-supported execution within a constrained task environment. As a result, the findings should be interpreted as evidence about execution autonomy under controlled workflow conditions rather than as a direct evaluation of fully autonomous AI systems in unconstrained real-world settings.
Third, the task itself was relatively structured and rule based. This was methodologically useful because it allowed the effects of autonomy to be isolated more clearly, but it also limits generalizability. In more ambiguous, creative, or socially complex tasks, the effects of autonomy may differ substantially. The present results are therefore most directly applicable to constrained digital workflows in which valid outputs can be defined through explicit rules.
Fourth, intervention occurrence was operationalized rather broadly. Because a session was classified as involving intervention whenever at least one edit, override, or rejection-related action occurred, the measure captured a wide range of user actions and may have obscured finer differences between conditions. The fact that intervention occurrence remained similarly high across all conditions suggests that this binary measure had limited sensitivity. The count-based and type-based analyses were therefore more informative, but future research could refine intervention measures further by distinguishing between low-impact and high-impact forms of intervention.
Finally, the study relied exclusively on behavioral log data. This was a deliberate strength of the design because it enabled objective measurement of task performance and user actions. However, it also means that the study cannot directly explain how participants subjectively experienced the different autonomy conditions. Constructs such as trust, perceived control, workload, and satisfaction were not measured directly. Future work could combine log-based behavioral data with self-report measures in order to better connect observable behavior with user perception (Lee & See, 2004; Hoff & Bashir, 2015; Dzindolet et al., 2003).
5.6 Practical Implications
The practical implications of the study are especially relevant for the design of AI-supported digital workflows. The findings suggest that higher execution autonomy can be beneficial when tasks are structured, rule based, and governed by explicit constraints. In such situations, allowing the system to take over more of the execution process can improve efficiency, reduce user errors, and lower the amount of corrective interaction required. This is particularly valuable in repetitive administrative or configuration-oriented workflows where the system can reliably generate valid outcomes. However, the results also show that user involvement remains important even under higher autonomy. Intervention did not disappear; rather, its frequency decreased and its form changed. This implies that designers should not assume that execution autonomy makes user control unnecessary. Instead, systems should be designed to support appropriate supervisory control. Even when the system executes actions directly, users should still be able to inspect outputs, understand what has been generated, and intervene when necessary (Lee & See, 2004; Endsley, 2017). This leads to a more differentiated design implication: higher autonomy appears especially useful when task rules are stable, the cost of system error is manageable, and output validity can be checked systematically. In contrast, stronger user control is likely to remain important when tasks are ambiguous, preference sensitive, high stakes, or difficult to evaluate automatically. Under such conditions, full execution autonomy may reduce effort, but it may also increase the need for transparency, reviewability, and correction mechanisms (Parasuraman et al., 2000; Endsley, 2017). The comparison between Assistance and Execution also suggests that full execution autonomy is not always required to achieve meaningful performance gains. In the present study, the move from Manual to system-supported conditions produced the strongest improvements, whereas the differences between Assistance and Execution were often smaller and not always statistically significant. From a design perspective, this means that assistance-oriented systems may already offer substantial value while preserving a greater degree of user agency. In many practical settings, the most effective design may therefore be neither full manual control nor unconditional full execution, but a calibrated level of autonomy that matches the structure, risk, and reversibility of the task. This conclusion is consistent with research showing that users often accept automation more readily when they retain some opportunity to shape or adjust the system’s output rather than merely accept a fixed automated result (Dietvorst et al., 2018; Miller & Parasuraman, 2007). Taken together, these findings support a design perspective in which autonomy should be calibrated rather than maximized. The central design goal should not be to eliminate user involvement, but to reduce unnecessary manual burden while preserving meaningful control where it is still needed.
5.7 Conclusion
This study investigated how different levels of AI execution autonomy influence user task performance and intervention behavior in a controlled digital workflow. Across the three autonomy conditions, the results showed that increasing execution autonomy was generally associated with improved task performance. In particular, higher autonomy reduced task completion time, lowered detected error occurrence, and was associated with lower abandonment compared with the Manual condition. At the same time, increased autonomy did not remove the user from the interaction process. Instead, it changed the nature of user involvement: intervention remained present across conditions, but its frequency decreased and its form shifted from direct manual configuration toward supervision, selective correction, and system-oriented adjustment. These findings contribute to the literature on human–automation interaction in two important ways. First, they extend the discussion from assistive automation toward execution-oriented AI systems, in which the system not only supports decision making but also takes over larger parts of task execution. Second, they provide behavior-based evidence derived from system-generated log data, thereby complementing prior research that has often focused more strongly on subjective constructs such as trust, reliance, and perceived usefulness. In this sense, the study shows that AI execution autonomy should not be understood simply as a substitution of machine action for human action, but rather as a redistribution of execution authority that reshapes both task outcomes and user intervention patterns. The results further suggest that the benefits of autonomy are especially evident in structured, rule-based workflows in which valid outputs can be generated and evaluated under clear constraints. However, the findings also indicate that higher autonomy does not make human control irrelevant. Even under more execution-oriented conditions, meaningful opportunities for user oversight, review, and correction remain essential. The central design implication is therefore not that more autonomy is always better, but that autonomy should be calibrated carefully to the demands, risks, and reversibility of the task environment. Overall, this study provides empirical evidence that AI execution autonomy can improve efficiency and reduce manual burden while preserving a continuing role for human supervision. By linking levels of execution autonomy to observable behavioral outcomes, it offers a more differentiated understanding of how control is redistributed in human–AI interaction and provides a foundation for future research on the design of effective and responsible execution-oriented AI systems.
References
Bainbridge, L. (1983). Ironies of automation. Automatica, 19(6), 775–779. https://doi.org/10.1016/0005-1098(83)90046-8
Dietvorst, B. J., Simmons, J. P., & Massey, C. (2015). Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology: General, 144(1), 114–126. https://doi.org/10.1037/xge0000033
Dietvorst, B. J., Simmons, J. P., & Massey, C. (2018). Overcoming algorithm aversion: People will use imperfect algorithms if they can (even slightly) modify them. Management Science, 64(3), 1155–1170. https://doi.org/10.1287/mnsc.2016.2643
Dzindolet, M. T., Peterson, S. A., Pomranky, R. A., Pierce, L. G., & Beck, H. P. (2003). The role of trust in automation reliance. International Journal of Human-Computer Studies, 58(6), 697–718. https://doi.org/10.1016/S1071-5819(03)00038-7
Endsley, M. R. (2017). From here to autonomy: Lessons learned from human–automation research. Human Factors, 59(1), 5–27. https://doi.org/10.1177/0018720816681350
Hoff, K. A., & Bashir, M. (2015). Trust in automation: Integrating empirical evidence on factors that influence trust. Human Factors, 57(3), 407–434. https://doi.org/10.1177/0018720814547570
Lee, J. D., & See, K. A. (2004). Trust in automation: Designing for appropriate reliance. Human Factors, 46(1), 50–80. https://doi.org/10.1518/hfes.46.1.50_30392
Miller, C. A., & Parasuraman, R. (2003). Beyond levels of automation: An architecture for more flexible human–automation collaboration. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 47(1), 182–186. https://doi.org/10.1177/154193120304700138
Miller, C. A., & Parasuraman, R. (2007). Designing for flexible interaction between humans and automation: Delegation interfaces for supervisory control. Human Factors, 49(1), 57–75. https://doi.org/10.1518/001872007779598037
Mosier, K. L., & Skitka, L. J. (1999). Automation use and automation bias. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 43(3), 344–348. https://doi.org/10.1177/154193129904300346
Parasuraman, R., & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2), 230–253. https://doi.org/10.1518/001872097778543886
Parasuraman, R., Sheridan, T. B., & Wickens, C. D. (2000). A model for types and levels of human interaction with automation. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, 30(3), 286–297. https://doi.org/10.1109/3468.844354
Parasuraman, R., & Wickens, C. D. (2008). Humans: Still vital after all these years of automation. Human Factors, 50(3), 511–520. https://doi.org/10.1518/001872008X312198
Sarter, N. B., & Woods, D. D. (1995). How in the world did we ever get into that mode? Mode error and awareness in supervisory control. Human Factors, 37(1), 5–19. https://doi.org/10.1518/001872095779049516
Sheridan, T. B., & Verplank, W. L. (1978). Human and computer control of undersea teleoperators (Technical Report). MIT Man-Machine Systems Laboratory.
Wickens, C. D., Li, H., Santamaria, A., Sebok, A., & Sarter, N. B. (2010). Stages and levels of automation: An integrated meta-analysis. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 54(4), 389–393. https://doi.org/10.1177/154193121005400425
Declaration of Independence
I certify that I have written this thesis independently and without the use of any aids other than those stated. All passages taken verbatim or in spirit from publications or other sources are marked as such.
Place, date: __________________________
Signature: __________________________